Examine the relationship between breaking news and exchange rates in Python.
I don’t trust almost everything about forex system trading. I don’t know if you can make money with a system that was developed by a huge …

In my previous article, I investigated data on the relationship between FX (currency exchange) rates and breaking news. In this article, I will consider a system that can classify and issue position orders using a machine learning (AI) NLP model as soon as it receives breaking news. The basic idea is detailed in my previous article.
This time, I will not write about the implementation and details of machine learning. The results are quite good, but I cannot be responsible for the trades, so I will not distribute the model.
For the past few years, BERT and its derivatives seem to be taking the world by storm in the field of NLP. So I’m going to use Electra, which is one of the most efficient learning methods out there. Also, it’s easier to use English as the target language, but in my case, as I’ll explain later, I’ll be focusing on Japanese news that comes out during Japanese trading hours, so the target language will be Japanese.
Electra Base model was used. For pre-training, we prepared our own model with the following training.
The amount of data that determines that a position should be L or S is quite small for USD/JPY and EUR/JPY. We also found that the accuracy of machine learning cannot be improved unless there are equal amounts of L, S, and do nothing data. For this reason, the currency pair used was the pound sterling, which has high volatility.
In addition, the training data is the Rxxters News data from 2016 to 2021, which I wrote about in my previous article, and filtered by the following conditions.
And labeling was done with the following.
Then, all the training data for label 1 and label 2 were replicated once (x2) and the data were overturned.
# Number of training data
{'0': 3625, '1': 2898, '2': 3050, '3': 126}
# Number of test data
{'0': 579, '1': 132, '2': 167, '3': 2}
The training data is still small. I would like to have 10 times more data, but I can’t prepare it this time, so this is it.
2 epoch training on a regular GPU (Tesla T4). It takes about 30 minutes to complete. Also trained with the pytorch framework. To be honest, I spent a whole day trying various tuning methods, but the results didn’t change much.
# News of 2021 that could be correctly classified.
749/880(0.8511)
It’s a good result. In other words, an AI trained on news data from 2016-2020 analyzed the news from 2021 and was able to guess the correct position about 85% of the time.
Let’s try a simulation using the model (AI) created here for the actual market period of 2021/1/1~2021/11/30. Since the period is already in the past, all the AI clustering has been done and the output is in CSV format as shown below.
label, date
0,20210104010100
2,20210104062600
2,20210104063600
2,20210104100700
0,20210105002200
:
This data represents something like a buy/sell order output by a machine learning model I created. For example, for the news that came out on 2021/01/04/06:26, “label=2” means to take an S position in GBPJPY. And the rules of the trade should be as follows. Maybe this following 7 is quite difficult in actual trade.
A simulation reflecting these conditions was prepared with the following code.
import math
import csv
def get_csv_data():
with open(f'GBPJPY.txt') as f:
reader = csv.reader(f)
ret = []
for row in reader: ret.append(row)
return ret
def get_result():
with open(f'result.CSV') as f:
reader = csv.reader(f)
dic = {}
for row in reader:
if row[0] == 0 or row[0] == 3: continue
dic[row[2]] = row[0]
return dic
def get_profit(csv, i, type_num):
l_or_s = 1
if type_num == 2: l_or_s = -1
if i >= len(csv): return 0
spread = 0
start = float(csv[i][3])
fix_profit_per = 1 + (0.0035 * l_or_s)
fix_profit_border_per = 0.0015 * l_or_s
fix_profit_border = 0
is_set_profit = False
loss_cut_per = 1 - (0.0025 * l_or_s)
end = i
for plus in range(99999):
end += plus
rate = float(csv[end][3])
if end >= (len(csv) - 1):
spread = (rate - start) * l_or_s
break
if rate < start * loss_cut_per and l_or_s == 1: # Loss Cut
spread = (rate - start) * l_or_s
break
elif rate > start * loss_cut_per and l_or_s == -1: # Loss Cut
spread = (rate - start) * l_or_s
break
if is_set_profit is False:
if rate > start * fix_profit_per and l_or_s == 1:
fix_profit_border = start * (fix_profit_per - fix_profit_border_per)
is_set_profit = True
elif rate < start * fix_profit_per and l_or_s == -1:
fix_profit_border = start * (fix_profit_per - fix_profit_border_per)
is_set_profit = True
else:
if rate < fix_profit_border and l_or_s == 1:
spread = (rate - start) * l_or_s
break
elif rate > fix_profit_border and l_or_s == -1:
spread = (rate - start) * l_or_s
break
if rate > (fix_profit_border + start * fix_profit_border_per) and l_or_s == 1:
fix_profit_border = rate - start * fix_profit_border_per
elif rate < (fix_profit_border + start * fix_profit_border_per) and l_or_s == -1:
fix_profit_border = rate - start * fix_profit_border_per
return spread, end
if __name__ == '__main__':
csv_data = get_csv_data()
result_dic = get_result()
asset_sum = 1000000
leverage = 10
unit = 10000
i = -1
end = 0
for c in csv_data:
i += 1
if i < end: continue
result_data = result_dic.get(c[1] + c[2])
if result_data is None: continue
rate = float(csv_data[i + 1][3])
position_unit = math.floor((asset_sum * leverage) / (unit * rate))
spread, end = get_prof(csv_data, i + 1, result_data)
asset_sum += position_unit * unit * spread
print(math.floor(asset_sum))
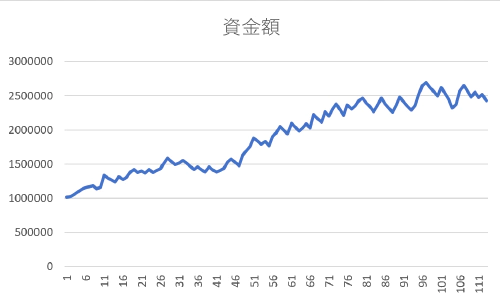
He made 113 trades in all, and his 1 million yen has grown to almost 2.5 million yen! No way, right?
To be honest, the number of attempts may be too small and the high leverage may just happen to be working. However, I was surprised to see a nice increase after 113 trades over 11 months. As I mentioned earlier, I think it is probably difficult to slide the stop-loss price for profit, so it may not perform like this in reality. Also, I don’t trust system trades because it’s common for them to work well in simulations but fall apart in actual trades.
Hmmm. I wasn’t expecting it to work this well at all. The actual trading is done as follows. It seems that there is no Japanese FX company that can trade with API, so the trade itself needs to be done manually by a human. Too bad.
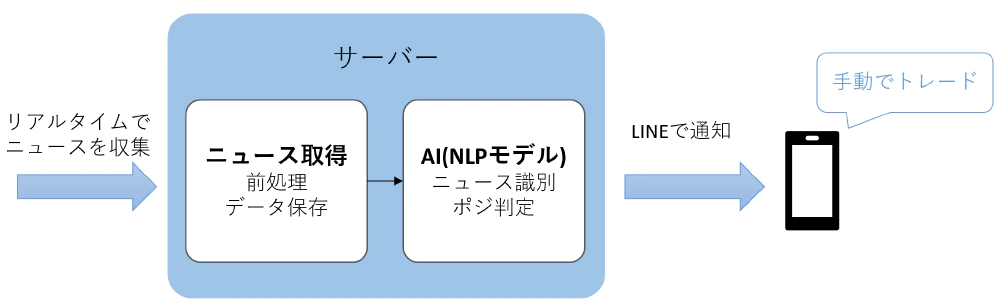
Keep up with the latest news and run it through a machine learning model to make a decision each time. If it decides that a position should be taken, it notifies me on line. Immediately after that, open the forex app and take a L or S position. The rest is settled according to the above rules. After registering as a developer, you can easily send the API with the following code.
import requests
def send_line(text):
response = requests.post(
'https://api.line.me/v2/bot/message/push',
json={
"to": "toid",
"messages":[
{
"type":"text",
"text":text
}
]
},
headers={
"Authorization": "Bearer TOKEN"
}
)
Also, once a month, we do additional training of the machine learning model. As more and more currency news comes out in a month, the AI is updated and enhanced to determine the latest information.
But after writing all this, I’m thinking that the world isn’t that naive. Isn’t it obvious that things are going too well? The above line graph looks like something you’d see on a scam website.
What I was concerned about was the continuity of economic news, but in this model, the decision was based on only one news. So, for example, if there is a “Fed hints at rate hike” followed by a “Fed leaves rates unchanged”, the second news would be too strong and you would have to reconsider your position, but in this model, the first news is given priority. Also, since the rate fluctuates greatly when there is a “big gap” between the two news, it is obviously not right to judge the news one by one.

Written By Ason
I am a small business owner who wants to be a programmer forever. The only thing I can be proud of is that I have a good bowel movement. I am an expert at defecation.
I don’t trust almost everything about forex system trading. I don’t know if you can make money with a system that was developed by a huge …

Somehow, being bad can be fascinating. Probably anyone who was born between the 1970s and early 1990s and touched a PC during their school days has …